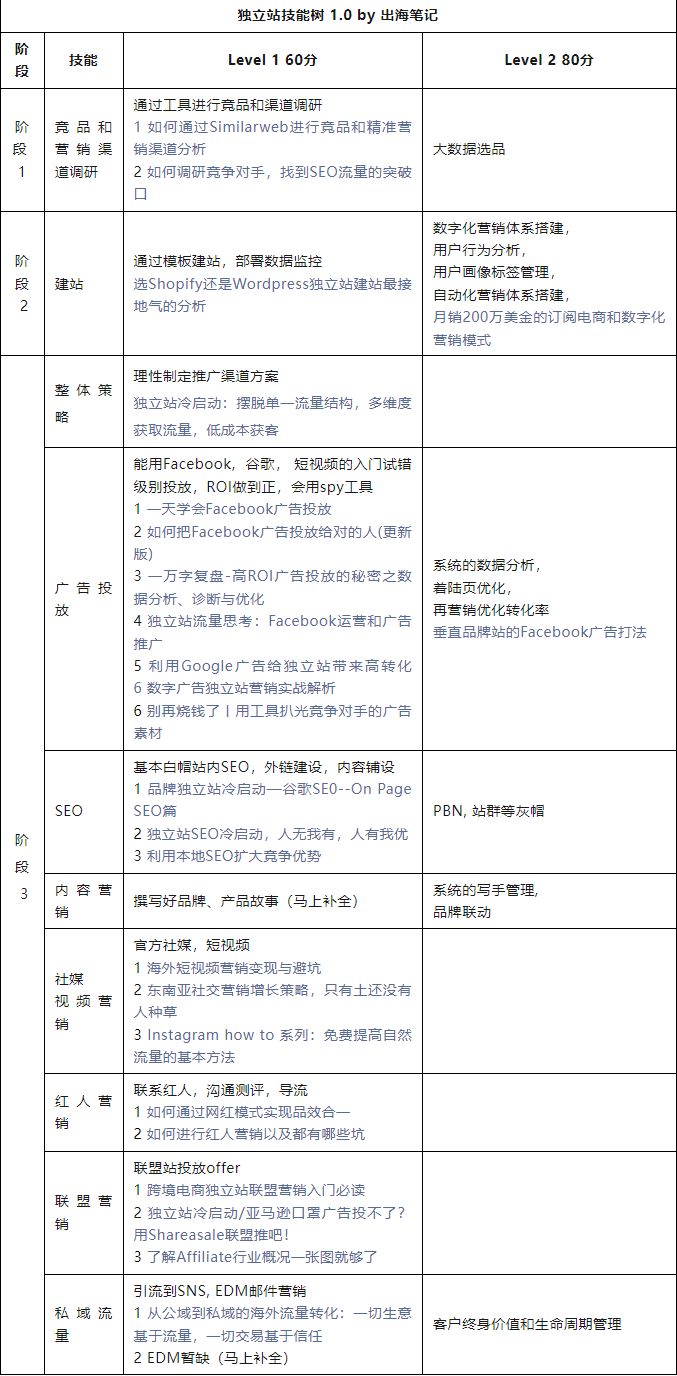
任务:基于 flare 文本数据,建立 LSTM 模型,预测序列文字
1.完成数据预处理,将文字序列数据转化为可用于LSTM输入的数据
2.查看文字数据预处理后的数据结构,并进行数据分离操作
3.针对字符串输入(" flare is a teacher in ai industry. He obtained his phd in Australia."),预测其对应的后续字符
参考视频:吹爆!3小时搞懂!【RNN循环神经网络+时间序列LSTM深度学习模型】学不会UP主下跪!
部分参数与视频不同
pre.py
import numpy as np
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from model import LSTM
# 加载数据
data = open('flare').read()
# 移除换行符
data = data.replace('\n','').replace('\r','')
# print(data)
# 字符去重
letters = list(set(data))
num_letters = len(letters)
# print(letters)
# print(len(letters))
# 建立字典
int_to_char = {a:b for a,b in enumerate(letters)}
# print(int_to_char)
char_to_int = {b:a for a,b in enumerate(letters)}
# print(char_to_int)
time_step = 10
# 滑动窗口提取数据
def extract_data(data, slide):
x = []
y = []
for i in range(len(data) - slide):
x.append([a for a in data[i : i + slide]])
y.append(data[i+slide])
return x,y
# 字符到数字的批量转化
def char_to_int_Data(x, y, chat_to_int):
x_to_int = []
y_to_int = []
for i in range(len(x)):
x_to_int.append([char_to_int[char] for char in x[i]])
y_to_int.append([char_to_int[char] for char in y[i]])
return x_to_int, y_to_int
# 实现输入字符文章的批量处理,输入整个字符,滑动窗口大小,转化字典
def data_preprocessing(data, slide, num_letters, char_to_int):
char_Data = extract_data(data, slide)
int_Data = char_to_int_Data(char_Data[0], char_Data[1], char_to_int)
Input = int_Data[0]
Output = list(np.array(int_Data[1]).flatten())
Input_RESHAPED = np.array(Input).reshape(len(Input), slide)
new = np.random.randint(0, 10, size=[Input_RESHAPED.shape[0], Input_RESHAPED.shape[1], num_letters])
for i in range(Input_RESHAPED.shape[0]):
for j in range(Input_RESHAPED.shape[1]):
new[i, j, :] = torch.nn.functional.one_hot(torch.tensor(Input_RESHAPED[i, j], dtype=torch.long), num_classes = num_letters)
return new, Output
x,y = data_preprocessing(data, time_step, num_letters, char_to_int)
# print(y)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=10)
# print(x_train.shape, len(y_train))
y_train_category = torch.nn.functional.one_hot(torch.tensor(y_train, dtype=torch.long), num_letters)
# print(y_train_category)
# 将数据转换为 PyTorch 的 Tensor
x_train_tensor = torch.tensor(x_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
x_test_tensor = torch.tensor(x_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
model.py
import torch
from torch import nn
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers, dropout_prob=0.2):
super(LSTM, self).__init__()
# 定义LSTM层
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout_prob)
# 定义Dropout层
self.dropout = nn.Dropout(dropout_prob) # Dropout层,用于在全连接层前丢弃部分神经元
# 定义全连接层
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# LSTM输出
out, _ = self.lstm(x)
# LSTM输出的最后一个时间步
out = out[:, -1, :]
# Dropout层
out = self.dropout(out)
# 全连接层输出
out = self.fc(out)
return out
train.py
import numpy as np
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from model import LSTM
from pre import *
# 定义模型参数
input_size = num_letters # 输入大小等于字母集的大小
hidden_size = 256 # 隐藏层大小
output_size = num_letters # 输出大小(预测下一个字符)
num_layers = 2 # LSTM层数
# 实例化模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LSTM(input_size, hidden_size, output_size, num_layers).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(reduction = 'mean')
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 创建 DataLoader
train_dataset = TensorDataset(x_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 训练模型
num_epochs = 10
best_accuracy = 0.0 # 用于保存最好的模型
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, targets in train_loader:
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
# 你可以在每个 epoch 后验证模型并保存最佳模型
model.eval()
with torch.no_grad():
x_test_tensor = torch.tensor(x_test, dtype=torch.float32).to(device)
y_test_tensor = torch.tensor(y_test, dtype=torch.long).to(device)
outputs = model(x_test_tensor)
_, predicted = torch.max(outputs, dim=1)
correct = (predicted == y_test_tensor).sum().item()
accuracy = correct / y_test_tensor.size(0)
print(f'Epoch [{epoch+1}/{num_epochs}], Test Accuracy: {accuracy * 100:.2f}%')
# 如果模型的准确率提升了,则保存模型
if accuracy > best_accuracy:
best_accuracy = accuracy
torch.save(model.state_dict(), 'best_lstm_model.pth')
print("Model saved!")
# 最后保存最终模型
torch.save(model.state_dict(), 'final_lstm_model.pth')
# # 测试模型
# model.eval()
# with torch.no_grad():
# x_test_tensor = torch.tensor(x_test, dtype=torch.float32).to(device) # 确保测试数据在设备上
# y_test_tensor = torch.tensor(y_test, dtype=torch.long).to(device) # 确保测试标签在设备上
# # 前向传播
# outputs = model(x_test_tensor)
# _, predicted = torch.max(outputs, dim=1) # 获取预测类别的索引
# # 计算准确率
# correct = (predicted == y_test_tensor).sum().item()
# accuracy = correct / y_test_tensor.size(0)
# print(f'Test Accuracy: {accuracy * 100:.2f}%')
test.py
import torch
from model import LSTM
from pre import * # 确保 'pre' 模块中包含了数据处理的相关代码
from sklearn.metrics import accuracy_score
# 定义设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义模型参数(与训练时的参数一致)
input_size = num_letters # 输入大小等于字母表的大小
hidden_size = 256 # 隐藏层大小
output_size = num_letters # 输出大小(预测下一个字符)
num_layers = 2 # LSTM层数
# 实例化模型并加载训练好的参数
model = LSTM(input_size, hidden_size, output_size, num_layers).to(device)
model.load_state_dict(torch.load('best_lstm_model.pth')) # 加载你保存的最佳模型
model.eval() # 设置为评估模式
# 需要预测的新的字符串
new_string = "flare is a teacher in ai industry. He obtained his phd in Australia."
# 预处理输入数据:将新字符串转换为适合模型输入的张量形式
X_new, y_new = data_preprocessing(new_string, time_step, num_letters, char_to_int) # 使用相同的预处理函数
X_new_tensor = torch.tensor(X_new, dtype=torch.float32).to(device)
y_new_tensor = torch.tensor(y_new, dtype=torch.long).to(device) # 实际的标签
# 进行预测
with torch.no_grad():
# 前向传播,获取模型的输出
outputs = model(X_new_tensor)
_, predicted_indices = torch.max(outputs, dim=1) # 获取每个时间步的预测类别
# 将预测的索引转换回字符
predicted_chars = [int_to_char[idx.item()] for idx in predicted_indices]
# 将真实的标签转换回字符
true_chars = [int_to_char[idx] for idx in y_new]
# 计算准确率
correct_predictions = (predicted_indices == y_new_tensor).sum().item()
total_predictions = len(y_new_tensor)
accuracy = correct_predictions / total_predictions
# 打印预测结果与准确率
print(f"Accuracy on new string: {accuracy * 100:.2f}%")
# 打印详细的预测信息
for i in range(len(new_string) - time_step):
print(f"Context: {new_string[i:i + time_step]} --> Predicted: {predicted_chars[i]}, Actual: {true_chars[i]}")










![[数据集][目标检测]智慧交通铁轨裂缝检测数据集VOC+YOLO格式4类别](https://i-blog.csdnimg.cn/direct/98f119a9b6384f9d93cda4f2906f041d.png)